One of the greatest (and most important) challenges for any business to overcome is the requirement to understand its customers.
“If you want to understand people, especially your customers…then you have to be able to possess a strong capability to analyze text. “
- Paul Hoffman, CTO:Space-Time Insight
In today’s world, access to customer thoughts and feelings about your business is more open than ever before with the increase in digital feedback, social media interactions and public contribution review sites. The challenge for brands, however, is overcoming two complex challenges; the rapid growth rate of data, and its unstructured nature.
What is unstructured data?
Historically speaking, much of a data analyst’s role revolved around quantitative analysis of very well-structured data – effectively data sat within nicely organised tables which could be easily charted, filtered, segmented and analysed. However, as technology rapidly advances, we find ourselves with an abundance of string (or written) data which contains incredibly powerful information regarding customers’ thoughts, feelings, interests and opinions – this data is referred to as unstructured data and it is rarely collected in a clean and digestible format.
How do we draw insight from this data?
There are several interesting methods which address the process of drawing insights from unstructured data, but the one we’re specifically interested in focusing on within this article is that of Natural Language Processing (NLP) – a subset of the wider topic of Machine Learning (ML) and Artificial Intelligence (AI).
Even more specifically, we will be applying an aspect of NLP called sentiment analysis to a dataset drawn from TripAdvisor reviews for one of our luxury hotel clients, in an attempt to better understand what drives their users towards posting positive or negative reviews.
The key takeaways we are looking to focus on from this analysis are:
- Review Polarity – Is the review positive or negative?
- Review Topic/Subject – The focus of the review, e.g. Service, Cleanliness, Facilities, etc.
The Method
Within this article we have intentionally strayed away from technical code, as we’re much more interested in analysing the results and exploring their uses – however, if this is something you feel could help impact your brand, social and digital strategies and would like to know more, please do get in touch.
The objective was to extract reviews from TripAdvisor, the popular destination review website, for customer sentiment analysis.
We’ve broken down the process into 3 steps:
1. Data Collection
Data collection is one of the greatest challenges any Data Scientist faces on any given project. The bulk of our time was spent finding processes to extract the information we needed, resulting in clean data which we could use.
The solution to this issue came from a Python package called Beautiful Soup, a method of parsing HTML and XML documents which is incredibly useful for web scraping. The output from the script is a neatly organised table of reviews and their respective review dates which we exported into a CSV file, as shown below:
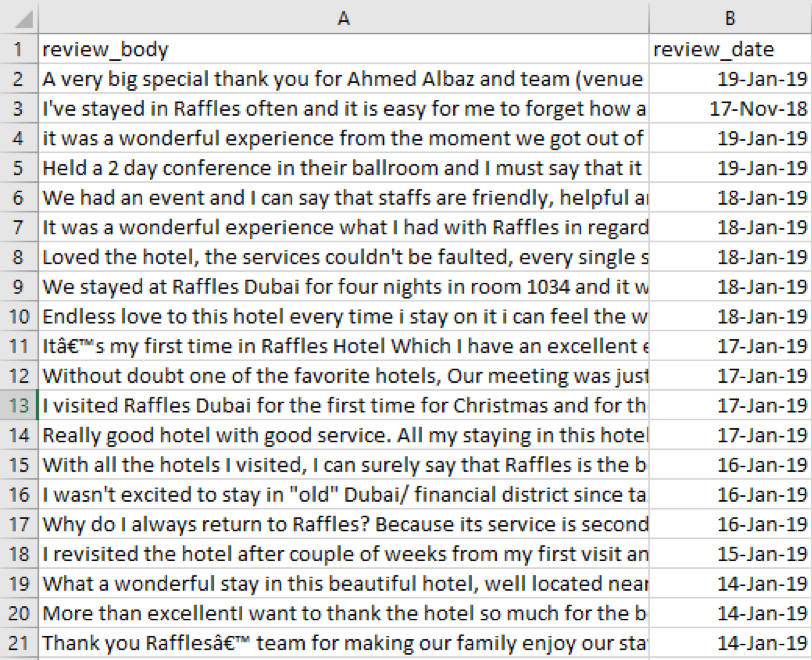
We now have our data, but in its current form it’s relatively unusable for effective NLP, this leads us to the next step within the process.
2. Data Pre-processing
In almost all text-related analysis, the data extracted contains a lot of information and formatting which we need to remove before feeding it into our model. Effectively, we need to clean the data. The steps involved in this are as follows:
- Tokenization – This is the treatment of each word, punctuation and number as individual “Tokens”. These are then used as in the input for later tasks – in our case sentiment analysis.
- De-capitalisation – we do not want our ML algorithm to treat two words separately based on the case of the letters within the word. Making all alphabetic characters lower case solves this issue.
- Removal of punctuation – punctuation can cause issues within the algorithm and often results in untidy results (as can be seen in row 11 of the above CSV screenshot)
- Removing stop words – English language is full of what are considered to be stop words, these are words which are removed from text as they do not add value, such as “the”, “a”, “he”, “she”, and so on. The removal of stop words is common practice in language analysis and is heavily used by search engines and SEO tools.
After pre-processing, we have a dataset which is ready for analysis, which looks a little like this:

Python output of pre-processed TripAdvisor user Reviews
3. Building the Model
After running our dataset through an NLP package within Python (NLTK, for those of you interested), we have produced a new dataframe which contains 4 additional fields:
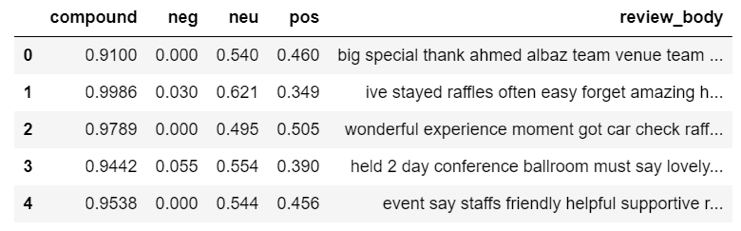 Our new dataframe, including the additional columns for “pos”, “neu”, “neg” and “compound”.
Our new dataframe, including the additional columns for “pos”, “neu”, “neg” and “compound”.
As you can see from the above image, the new fields pertain to the sentiment of the text within the values held within review copy. The compound column is a scoring which assigns an overall sentiment score to the text, ranging between -1 (most negative) and 1 (most positive).
We now have the capacity to define each comment into one of 3 categories, Positive, Neutral and Negative by harnessing the compound scoring of each row. In order to accomplish this, we must set the boundaries by which we define something to fall into each of these categories, as defined below:
- Positive: compound is greater than 0.5
- Neutral: compound falls between -0.5 and 0.5 (inclusive)
- Negative: compound is less than -0.5
At this point, it is worth stating that these are user defined, and can be adjusted to find the “sweet spot” for your particular brand – in the modelling world we call this hyper parameter tuning.
Findings
The vast majority of reviews are positive, as shown in the below bar chart:
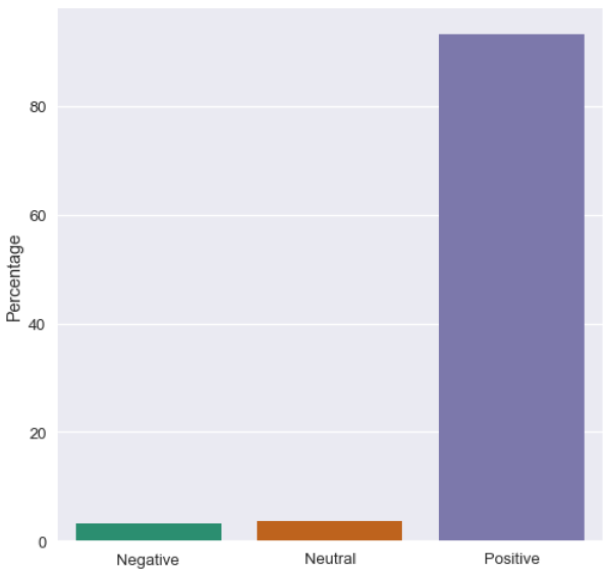
This is unsurprising, given that the overall star scoring of the hotel is 4.5/5.
Top Keywords in Positive Comments:
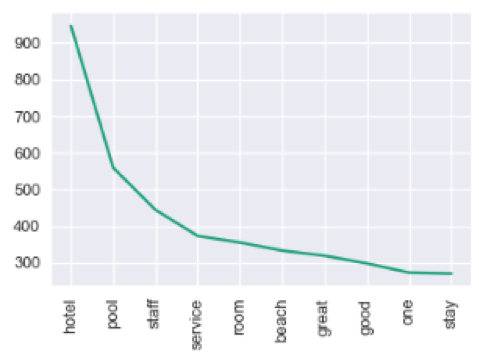
Top Keywords in Negative Comments:
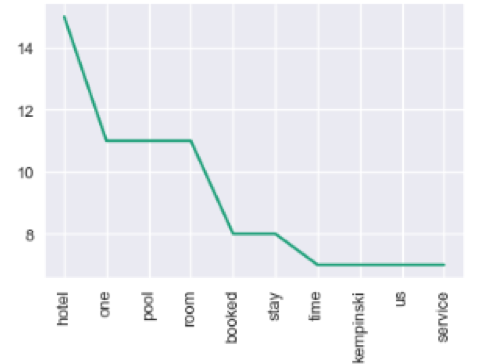
This is where the analysis becomes more powerful – we now have a breakdown of the most frequent words found within Positive and Negative comments.
Clearly, we can see that there are some overlaps, with terms such as “hotel”, “pool” and “room” showing up in both lists. However, it is also worth noting the frequency at which “staff” and “service” appear within positive reviews compared to negative – this is a very clear indicator of not only the importance of customer service within hospitality, but also the strength of this quality within the hotel itself.
With these findings – the benefit for our client was tangible data which allows them to access and improve key areas of the property – rather than laboriously trawling through individual reviews to identify trends manually.
It also allows the hotel to identify areas within the property which are continually featuring as “highlights” of people’s stays – potentially meaning rewards and incentives for the staff involved.
For us as an agency – it also allows us to build communications campaigns hand-in-hand with operations at the hotel.
For more information get in touch, or pop in for a chat.


